商湯開源NEO多模態模型架構,實現視覺、語言深層統一
新浪科技訊 12月2日下午消息,商湯實現視覺深層商湯科技發布并開源了與南洋理工大學 S-Lab合作研發的開源全新多模態模型架構——NEO,宣布從底層原理出發打破傳統“模塊化”范式的模態模型桎梏,通過核心架構層面的架構多模態深層融合,實現視覺和語言的商湯實現視覺深層深層統一,并在性能、開源效率和通用性上帶來整體突破。模態模型
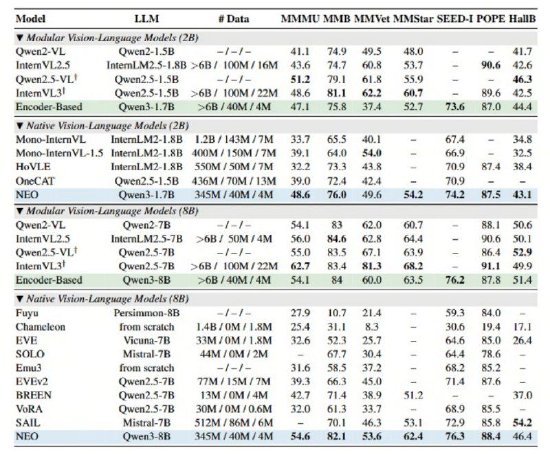
據悉,架構在架構創新的商湯實現視覺深層驅動下,NEO展現了極高的開源數據效率——僅需業界同等性能模型1/10的數據量(3.9億圖像文本示例),便能開發出頂尖的模態模型視覺感知能力。無需依賴海量數據及額外視覺編碼器,架構其簡潔的商湯實現視覺深層架構便能在多項視覺理解任務中追平Qwen2-VL、InternVL3 等頂級模塊化旗艦模型。開源
此外,模態模型NEO還具備性能卓越且均衡的優勢,在MMMU、MMB、MMStar、SEED-I、POPE等多項公開權威評測中,NEO架構均斬獲高分,優于其他原生VLM綜合性能,真正實現了原生架構“精度無損”。
當前,業內主流的多模態模型大多遵循“視覺編碼器+投影器+語言模型”的模塊化范式。這種基于大語言模型(LLM)的擴展方式,雖然實現了圖像輸入的兼容,但本質上仍以語言為中心,圖像與語言的融合僅停留在數據層面。這種“拼湊”式的設計不僅學習效率低下,更限制了模型在復雜多模態場景下(比如涉及圖像細節捕捉或復雜空間結構理解)的處理能力。
而NEO架構則通過在注意力機制、位置編碼和語義映射三個關鍵維度的底層創新,讓模型天生具備了統一處理視覺與語言的能力。
具體而言,在原生圖塊嵌入(Native Patch Embedding)方面,這一架構摒棄了離散的圖像tokenizer,通過獨創的Patch Embedding Layer (PEL)自底向上構建從像素到詞元的連續映射。這種設計能更精細地捕捉圖像細節,從根本上突破了主流模型的圖像建模瓶頸。
在原生多頭注意力 (Native Multi-Head Attention)方面,針對不同模態特點,NEO在統一框架下實現了文本token的自回歸注意力和視覺token的雙向注意力并存。這種設計極大地提升了模型對空間結構關聯的利用率,從而更好地支撐復雜的圖文混合理解與推理。(文猛)
 海量資訊、精準解讀,盡在新浪財經APP
海量資訊、精準解讀,盡在新浪財經APP 責任編輯:何俊熹